020-36204208






新闻资讯
NEWS & INFORMATION
【精选】Audio Vivid标准关键技术研究及系统试验
NO.1 编解码及渲染技术框架
Audio Vivid支持基于声道的音频信号(声道信号)、基于对象的音频信号(对象信号)和基于场景的音频信号(HOA信号)的音频编码和元数据编码。音频编码可采用通用码率音频编码,在保证听音质量的前提下对音频信号进行编码,也可采用《信息技术 高效多媒体编码 第3部分:音频》(GB/T 33475.3—2018)规定的无损音频编码,在数据无损的情况下实现音频信号的压缩。音频编码既支持声道信号、对象信号和HOA信号的单独编码,也支持声道+对象、HOA+对象等的混合编码。编码后的位流通过三维声位流复用得到三维声编码位流。Audio Vivid编码框架见图1。
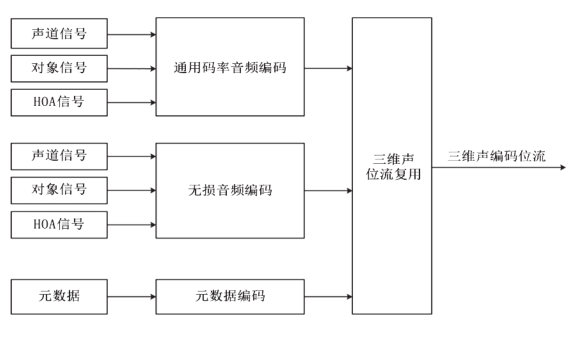
图1 Audio Vivid编码框架
Audio Vivid解码是编码的逆过程,通用码率音频解码或无损音频解码得到声道信号、对象信号、HOA信号,通过元数据解码恢复元数据信息。根据不同的终端重放环境,可通过扬声器渲染得到对应扬声器布局的信号用于扬声器播放,也可通过双耳渲染得到左右两路信号用于耳机播放。Audio Vivid解码和渲染框架见图2。
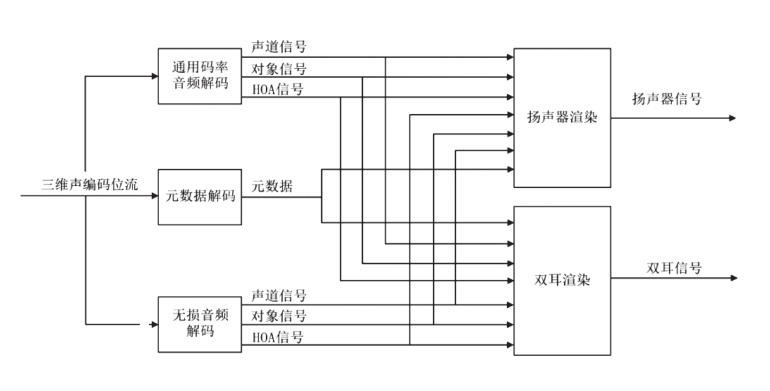
图2 Audio Vivid解码和渲染框架
NO.2 通用码率音频编解码关键技术
2.1 编解码框架和流程
通用码率音频编码包括核心编码和HOA空间编码。核心编码由编码预处理、下混和神经网络变换与量化编码组成。编码预处理将声道信号从时域转换为频域进行预处理,包括暂态检测、窗型判断、改进离散余弦变换(MDCT)、频域噪声整形、时域噪声整形、频带扩展编码;下混将编码预处理后的频域信号进行下混,去除声道间的相关性,包括双声道立体声下混、多声道下混、HOA下混;神经网络变换与量化编码采用基于神经网络的方式对下混后的信号进行变换、量化和编码得到二进制位流。HOA信号经过HOA空间编码后,再通过核心编码得到二进制位流。编码后的位流和元数据编码位流经过位流复用得到编码位流。通用码率音频编码框架示意图见图3。
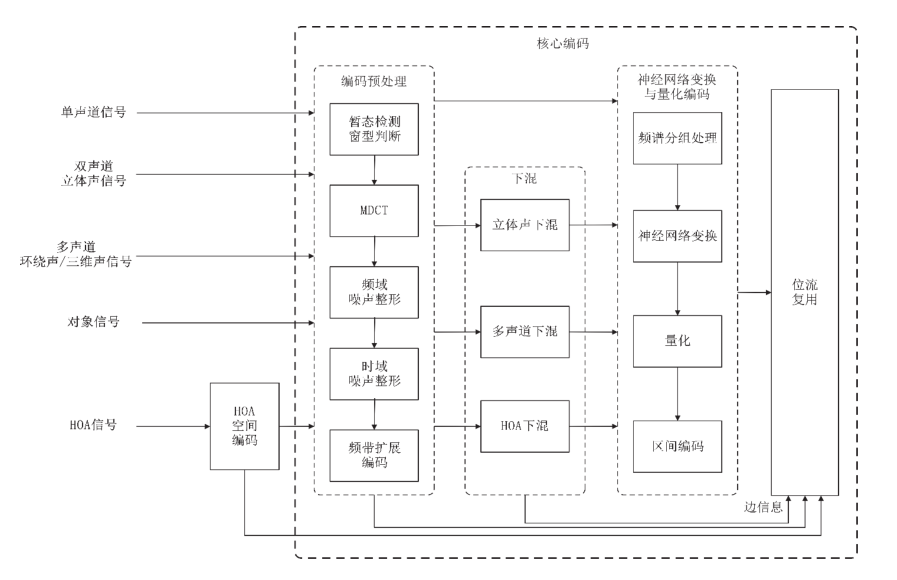
图3 通用码率音频编码框架
通用码率音频解码对编码后的位流进行解复用,经过包括解码逆量化和神经网络逆变换、上混、解码后处理的核心解码处理后恢复得到单声道信号、双声道立体声信号、多声道信号或对象信号。对于HOA解码,核心解码后的信号再经过HOA空间解码得到HOA信号。通用码率音频编码框架示意图见图4。单声道信号解码、双声道立体声信号解码、多声道信号解码和HOA空间解码过程是对应编码过程的逆过程,在此不再赘述。
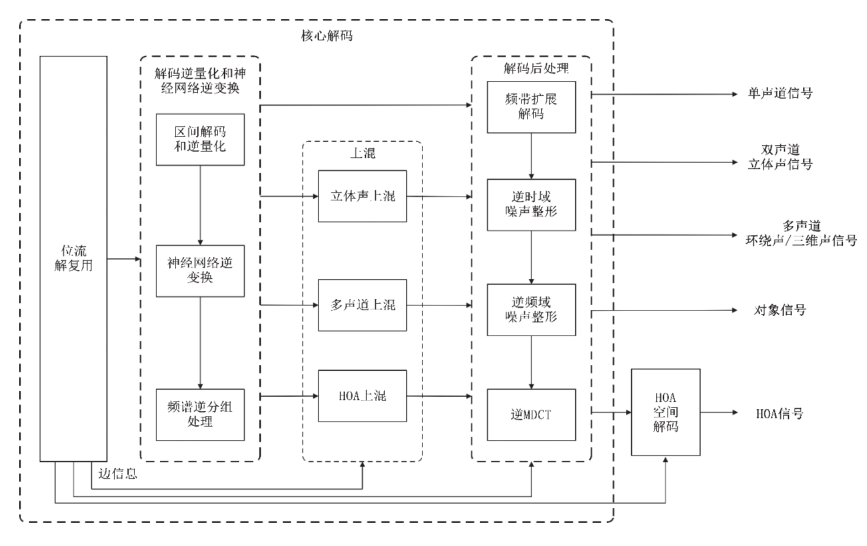
图4 通用码率音频解码框架
2.2 编解码关键技术
2.2.1 暂态信号检测和MDCT
一帧音频信号包含1024个样点,通过加窗将信号分为多个数据块,然后对每个数据块单独处理。首先对输入的音频信号进行暂态检测,判断当前信号是暂态信号还是稳态信号。对暂态信号加短窗以保证较好的时域分辨率,对稳态信号加长窗以保证较好的频域分辨率。
2.2.2 噪声整形
音频信号中的暂态信号从时域变换到频域后,存在大量的高频细节分量,量化时会产生量化噪声,经过反量化和反变换处理到时域后噪声会扩散,有部分噪声不能被掩蔽掉,会产生预回声和后回声现象,影响声音质量。
时域噪声整形(TNS)通过在频域对信号进行预测编码,解码端通过调节量化噪声的时域形状,来适应输入信号的时域形状,利用声音信号的掩蔽特性,将量化噪声由有用信号掩蔽掉。Audio Vivid通过采用两个可选频段的TNS滤波器实现时域噪声整形,将整个MDCT频谱划分为两个滤波器,分别覆盖[660Hz,5400Hz]和[5400Hz,20000Hz]。TNS滤波器使用的参数为反射系数(最大阶数为8),是LPC、LSF等参数的等价表示。在TNS滤波器对应的频率范围内,对该频率范围内的MDCT频谱进行基于反射系数的线性预测分析滤波,所得结果为TNS处理后的MDCT频谱。频域噪声整形(FDNS)控制编码过程引入的量化噪声在频域上的分布情况,利用人耳听觉掩蔽效应减少可感知的量化噪声,提升编码质量。Audio Vivid的频域噪声整形算法为基于LPC参数的MDCT频谱整形技术,包括信号预加重、自相关系数计算、LPC参数求解、LPC转换为LSF、LSF参数量化编码、频谱整形等处理。
2.2.3 频带扩展
频带扩展利用MDCT频谱高低频之间的相关性,在解码端根据解码所得核心带频谱重建原始信号的高频带频谱,在节省编码带宽的同时又能恢复出高频细节特征。
Audio Vivid中频带扩展算法在编码端计算每个高频频带的MDCT频谱能量,作为频带扩展的高频子带包络参数。根据源频率区域和目标频率区域的频谱特征,确定高频白化等级。解码端根据高频子带包络参数和白化等级恢复出高频频谱。
2.2.4 神经网络变换与熵编码
为了有效提升编码效率,Audio Vivid采用了基于神经网络的变换和熵编码技术。利用基础编码神经网络将MDCT信号转换为隐特征信号,再对隐特征信号做量化和熵编码。生成隐特征信号的目的是为了获得更利于高效熵编码的特征。隐特征在做熵编码前首先进行标量量化。标量量化的量阶大小由目标编码码率控制。标量量化后的隐特征信号被送入基于神经网络的熵编码模块。熵编码模块利用上下文编码神经网络生成待编码隐特征信号的上下文,根据该上下文选择对应的码书对隐特征信号进行熵编码。两个深度神经网络是联合训练的,在最小化信息熵的约束下联合寻找待编码特征、上下文和各码书之间的关系,充分利用了深度神经网络的强大抽象能力。两个深度神经网络在编码端和解码端采用了非对称的设计,即编码端采用较大的神经网络保证较高的压缩效率,而解码端采用较小的神经网络以降低开销。基于神经网络的变换与编码技术架构见图5。

图5 神经网络变换与编码技术架构
基础编码神经网络的输入为长度1024的MDCT频谱,经神经网络变换后,得到的变换系数维度为16通道,每个通道64个系数。
上下文编码神经网络结构配置相关信息见表2。上下文编码神经网络的输入为16通道,每个通道64维的变换系数,经神经网络变换后,得到的上下文编码神经网络的变换系数,通道数仍为16,每个通道16维。
2.2.5 HOA空间编码
对于一个m阶的HOA信号,具有(m+1)2个音频通道,如三阶HOA信号具有16个音频通道。HOA信号也可以看作一种多声道音频信号,采用多声道编码的方式直接进行压缩,但需要压缩的数据量随着阶数的增长显著提升。为了进一步降低分配到多声道核心编码器音频信号之间的相关性,Audio Vivid采用HOA空间编码,将HOA音频通道信号转化到一系列虚拟扬声器信号中,用以降低冗余,提高编码效率。
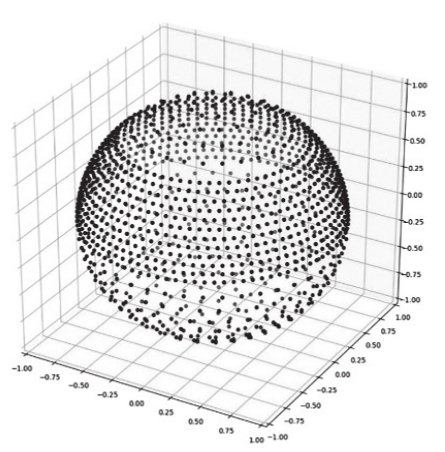
图6 虚拟扬声器分布
HOA空间编码技术假设待编码HOA信号的周围分布了若干虚拟扬声器,如图6所示。待编码的HOA信号可以由少数虚拟扬声器信号的HOA表达来近似,原始HOA信号和该近似表达信号的差值为残差信号,编码时只需要对少数虚拟扬声器信号的HOA表达和残差信号进行编码。少数虚拟扬声器信号的HOA表达可以进一步分解为虚拟扬声器HOA系数矩阵与虚拟扬声器信号向量。HOA系数矩阵编码只需将虚拟扬声器的位置信息作为边信息编码。虚拟扬声器信号由待编码HOA信号在选定的少数虚拟扬声器上的投影确定。
由于少数虚拟扬声器的数量远小于待编码HOA信号的通道数,残差信号可以用相对较少的比特编码,虚拟扬声器位置边信息的数据量又很小,因而编码效率大幅提升。
NO.3元数据编码
Audio Vivid支持ITU-R BS.2076标准中规定的元数据,并对部分元素和属性进行了进一步限定以便用于后续编码,如将audioProgrammeName的长度规定为32个字节以内。此外,也支持后续根据实际应用需求对元数据进一步扩展。
元数据编码采用标量量化,根据取值范围确定量化步长和量化偏置,经过均匀量化后得到元数据编码位流,与音频编码位流一起复用为三维声编码位流。
NO.4 扬声器渲染和双耳渲染
4.1 扬声器渲染
扬声器渲染将输入的元数据和音频数据根据特定的重放配置,渲染出用于重放的音频信号。扬声器渲染分为基于声道的渲染、基于对象的渲染和基于HOA的渲染。基于声道的渲染将输入声道信号转换为目标扬声器布局所需的信号,基于对象的渲染和基于HOA的渲染利用元数据和重放配置再现基于对象和基于HOA的音频数据。根据实际应用需求,三种渲染方式可组合使用,也可单独使用。
基于声道的渲染根据输入声道的位置,结合目标扬声器布局,确定每个声道信号的增益。若输入声道数与输出声道数不相等,采用点声源定位,由实际扬声器虚拟出对应输出位置。点声源定位使用三角形区域方法来处理,由三个扬声器形成的球形三角形区域实现基本的VBAP来获得虚拟扬声器的位置。当输入为5.1声道且目标扬声器布局中音箱个数小于3时,采用立体声下混方式,将5.1声道信号下混为立体声信号。
基于对象的渲染根据输入的对象信号和对应的元数据,实现屏幕缩放、屏边锁定、声道锁定、发散、声像扩展、排除下混区域等处理,也采用基于VBAP技术进行对象渲染,利用 3个扬声器的位置向量计算得到虚拟声源的位置,假设声源和3个扬声器位于同一个球面上,将 3个扬声器的位置向量视为基向量,虚拟声源的位置由它们的线性组合得到。
基于HOA的渲染采用基于AllRAD的方法,计算出每一HOA轨道对应音箱的增益值,将多轨HOA信号输出给独立的音箱。通过AllRAD的矩阵,将HOA信号分解为均匀分布在球体上的虚拟扬声器,并在实际扬声器上通过点声源定位生成虚拟扬声器信号。
4.2 双耳渲染
双耳渲染采用基于Ambisonic的声场重建技术,使用球谐函数将输入音频按照元数据编码到球谐域,以Ambisonic格式作为中间介质信号存储,空间编码包括声道音频的空间编码和对象音频的空间编码。由于HOA音频本身是Ambisonic格式,只需要叠加到中间介质信号上,无需进行空间编码。空间编码时需对声源位置参数进行坐标变换才能使用,同时空间编码也需要对元数据中的控制参数和用户交互进行响应。最后将Ambisonic信号经空间解码后输出双耳音频。参数计算是对控制参数进行计算和转换,例如位置参数坐标系变换,对象音频位置更新等。
NO.5 Audio Vivid端到端直播系统搭建及试验
为了加快Audio Vivid标准的应用部署,卡塔尔世界杯期间中央广播电视总台搭建了基于Audio Vivid的广播级端到端直播试验系统,试验系统部署在总台光华路办公区6层音频岛,制作域和传输编码域部署在第十一录音合成机房,家庭展示环境部署在第八录音合成机房三维声审听室。制作域和家庭展示环境的音箱布局均采用GY/T 316中4+5+0扬声器配置。Audio Vivid端到端直播试验系统框图见图7。

图7 Audio Vivid端到端直播试验系统框图
主控回传的卡塔尔世界杯赛事音频信号为10通道三维声声床信号(3声道为中文评论)和6通道对象信号,对象信号包括1通道英文评论信号、1通道“Close Ball”信号(踢球声)、1通道 “Audio follow Video”(画面声)、1通道现场广播/音乐和2通道球迷声信号。音频信号在音频制作系统中经过声道倒换、电平调整等制作后生成为5.1.4声床+6个对象的16通道PGM信号,然后通过交换机以ST 2110-30[5]的方式分别传输至编码器和Audio Vivid制作工具。Audio Vivid制作工具支持ITU-R BS.2076-2规定的元数据制作,可对各通道音频信号、交互等元数据进行配置,生成的元数据信号使用HTTP协议通过交换机传输至编码器。同时,Audio Vivid制作工具将16通道PGM信号实时渲染生成为三维声监听信号并传输至音频制作系统进行监听。视频信号为4K超高清信号,不经过处理直接以ST 2110-20的方式传输至编码器。编码器实现4K超高清AVS3视频实时编码和Audio Vivid音频实时编码。本次试验中声床信号编码码率为256kbps,对象信号和元数据编码码率为192kbps,总的三维声音频编码码率为448kbps。编码后的音视频码流封装为TS流,并以HTTP的方式传输至家庭展示环境。
家庭展示环境部署了支持Audio Vivid解码的机顶盒,机顶盒对视音频编码信号解复用后分别解码。视频解码模块将4K 超高清视频编码信号经过AVS3解码后通过HDMI传输至4K电视显示。音频解码渲染模块将三维声编码信号经过Audio Vivid解码得到音频信号(声床信号和对象信号)和元数据。同时,音频解码渲染模块配置了三维声元数据交互接口,可接收解码元数据,并提供给用户交互界面(见图8),用户使用遥控器调整对象音量大小、位置等信息并生成控制信号,渲染器根据元数据信号、控制信号对音频信号实时渲染后通过机顶盒的模拟音频接口将音频信号送至不同的扬声器,在5.1.4多音箱环境下实现了个性化的听音体验。

图8 Audio Vivid终端用户交互界面
试验中提供了三种听音场景:1. 标准:可实现解说切换+球声+现场扩声交互体验;2. 主客队氛围:可实现解说切换+不同阵营球迷呐喊声切换+球声+现场扩声交互体验;3. 现场氛围:不同阵营球迷呐喊声切换+球声+现场扩声交互体验。
试验系统实现了基于广播电视直播链路的Audio Vivid端到端传输,特别是实现了元数据从制作到传输编码再到终端解码渲染的全流程打通,为今后Audio Vivid产业链端侧深化研发提供了宝贵的经验。
NO.6 小结
三维声在平面声场的基础上,增加了垂直方位的声场,可以对整个声音空间中的每个声音精准定位,将声场还原为更接近真实世界的三维声场,从而带来沉浸式的感受。Audio Vivid采用基于神经网络的变换和熵编码、HOA空间编码等压缩编码技术,可以有效去除三维声信号间的冗余,在保证编码质量的前提下节省传输带宽。此外,通过编码传输特定的对象元数据,在终端进行扬声器渲染或双耳渲染,就可以对单个对象的控制和交互,如语言选择、音量大小调整等,从而实现声音的交互化和个性化,极大提升用户听音体验。随着Audio Vivid技术标准和生态的进一步完善,用户将在更多的音频场景中感受到三维声带来的声临其境体验。
[1] ITU-R BS 2051. Advanced sound system for programme production [S]. International Telecommunication Union, 2014.
[2] 国家新闻出版广电总局. 用于节目制作的先进声音系统: GY/T 316—2018[S].
[3] ITU-R BS.2076. Audio Definition Model [S]. International Telecommunication Union, 2019.
[4] 国家广播电视总局. 三维声编解码及渲染: GY/T 363—2023[S].
[5] SMPTE ST 2110-30. Professional Media Over Managed IP Networks: PCM Digital Audio [S]. Society of Motion Picture and Television Engineers, 2017.
[6] SMPTE ST 2110-20. Professional Media Over Managed IP Networks: Uncompressed Active Video[S]. Society of Motion Picture and Television Engineers, 2017.